랜덤 INSERT 수행 시 페이지 분할과 병합을 최소화할 수 있는 fill factor 설정 값 확인
테스트 환경
- Aurora MySQL (t3.medium)
테스트 절차
1. fill factor 기본 값에서 md5(uuid())로 1,000,000건 레코드 삽입
2. fill factor를 테스트 값으로 설정 (100 95 90 85 80 75)
3. fill factor를 적용하기 위해 Optimize table (테이블 리빌드)
4. 테이블 풀스캔으로 버퍼풀에 로드된 PK 페이지 개수 확인
5. DB 서버 재시작
6. 200번 반복
a. 10,000건 레코드 삽입
b. 10,000건 레코드 삭제
7. Optimize table
Iteration code ▼
for i in range(200):
# create connection pool for insert
pool = await aiomysql.create_pool(minsize=min_thread_num, maxsize=max_thread_num, **db_config)
async def execute_query(self, pool, table_num, query_exec_type):
try:
async with pool.acquire() as conn:
async with conn.cursor() as cur:
rnd_num=randrange(0, table_num)
await cur.execute(f"INSERT INTO test{rnd_num} (id, seq_1, seq_2, seq_3, name, remark, created_at, updated_at) VALUES (md5(uuid()), floor(rand()*1000000), floor(rand()*1000000), floor(rand()*1000000), left(uuid(), 4), concat('test', floor(rand()*10)), now(), now())")
await conn.commit()
except Exception as e:
print(f"ERROR: {e}")
# create count record
tasks = [execute_query(self, pool, table_num, query_exec_type) for j in range(iteration_num)]
# execute asyncio
await asyncio.gather(*tasks)
# close pool
pool.close()
await pool.wait_closed()
# create connection pool for delete
pool = await aiomysql.create_pool(minsize=1, maxsize=1, **db_config)
async def execute_query(self, pool, table_num, query_exec_type):
try:
async with pool.acquire() as conn:
async with conn.cursor() as cur:
rnd_num=randrange(0, table_num)
await cur.execute(f"DELETE FROM test{rnd_num} ORDER BY RAND() LIMIT 10000")
except Exception as e:
print(f"ERROR: {e}")
# create count record
tasks = [execute_query(self, pool, table_num, query_exec_type) for j in range(1)]
# execute asyncio
await asyncio.gather(*tasks)
# close pool
pool.close()
await pool.wait_closed()
return self.start_time
innodb_fill_factor (75, 80, 85, 90, 95, 100)
## 테이블
CREATE TABLE `test0` (
`id` varchar(128) NOT NULL,
`seq_1` bigint DEFAULT NULL,
`seq_2` bigint DEFAULT NULL,
`seq_3` bigint DEFAULT NULL,
`name` varchar(10) DEFAULT NULL,
`remark` varchar(100) DEFAULT NULL,
`created_at` datetime DEFAULT NULL,
`updated_at` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `ix_seq1_seq2` (`seq_1`,`seq_2`),
KEY `ix_seq3` (`seq_3`),
KEY `ix_seq1_createdat` (`seq_1`,`created_at`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci## 1,000,000건 테이블 최적화 이후 버퍼풀에 로드된 PK 인덱스 페이지 개 수
mysql> SELECT count(*) FROM information_schema.INNODB_BUFFER_PAGE WHERE TABLE_NAME LIKE '%test0%' AND INDEX_NAME = 'primary';
+----------+
| count(*) |
+----------+
| 6431 |
+----------+
--> 1000000/6431 = 156 records(per PAGE)## 10,000건 레코드 INSERT
mysql> INSERT INTO test0 (id, seq_1, seq_2, seq_3, name, remark, created_at, updated_at)
VALUES (md5(uuid()), floor(rand()*1000000), floor(rand()*1000000), floor(rand()*1000000), left(uuid(), 4), concat('test', floor(rand()*10)), now(), now())
## 10,000건 레코드 DELETE
mysql> DELETE FROM test0 ORDER BY RAND() LIMIT 10000;
...
...
...(200번 반복)
테스트 결과
|
fill factor
|
페이지 분할 횟수
|
페이지 병합 시도 횟수
|
페이지 병합 성공 횟수
|
PK 인덱스 페이지 개수
|
|
75
|
1,172
(1706 Row당 페이지 분할)
|
4,072
|
1,133 (27%)
|
8095 -> 8275 (+180)
|
|
80
|
6,258
(319 Row당 페이지 분할)
|
17,541
|
6,082 (34%)
|
7546 -> 8004 (+458)
|
|
85
|
24,996
(80 Row당 페이지 분할)
|
84,131
|
24,293 (28%)
|
7117 -> 8237 (+1120)
|
|
90
|
77,562
(25 Row당 페이지 분할)
|
329,412
|
75,568 (22%)
|
6734 -> 8653 (+1919)
|
|
95
|
171,291
(11 Row당 페이지 분할)
|
848,566
|
166,881 (19%)
|
6349 -> 9481 (+3132)
|
|
100
|
244,606
(8 Row당 페이지 분할)
|
1,358,899
|
237,509 (17%)
|
6431 -> 9249 (+2818)
|
fill factor 75와 100의 측정 수치를 비교해보면 다음과 같다.
PK 기반 10,000의 레코드를 INSERT 한다고 가정하면,
- fill factor (75)
- 1706 Row당 페이지 분할이 1회 발생했으므로, 10,000개의 레코드를 INSERT 하는 경우 약 5.8번(10000/1706)의 페이지 분할이 필요
- fill factor (100)
- 8 Row당 페이지 분할이 1회 발생했으므로, 10,000개의 레코드를 INSERT 하는 경우 약 1250번(10000/1250)의 페이지 분할이 필요
innodb_fill_factor는 인덱스를 빌드하는 경우 B-tree 페이지의 공간 비율을 정의하는 옵션이다. 나도 헷갈려하고 있었지만, 여기서 중요한 것은 페이지 분할 시점에 fill factor가 결정되는 것이 아니라 테이블을 리빌드(인덱스 리빌드)할 때 fill factor가 결정된다는 것이다. 즉, 테이블을 리빌드하지 않는한 fill factor는 적용되지 않는다. 보통 기본값으로 적용하고 있는 fill factor 100은 테이블을 리빌드할 경우 페이지의 1/16 여유 공간만큼을 남겨둔다(이 기준은 고정이다). MySQL 서버에서는 테이블 리빌드가 자동으로 수행되지는 않기 때문에 신경쓰지 않아도 되는 중요도가 낮은 옵션일 수도 있다. 하지만 DB를 운영하다보면 테이블 리빌드가 필수적으로 수행되어야만 하는 경우도 있다. 특히 FULLTEXT INDEX를 추가해야 한다던지, 이전 포스팅에서와 같이 PK를 DROP하고, 다시 추가해야 한다던지, 컬럼을 삭제해야 한다던지 등(8.0.29부터는 다르게 적용됨) 모두 테이블 리빌드를 필요로 하는 작업들이다. DB 서버 성능을 전과 후로 비교할 때 innodb_fill_factor의 변경은 비교를 어떻게 해야하나 고민이 되기도 하는데 위 테스트에 다른 지표들까지 얹어서 비교해보면(CPU 사용량이 올라갔는지, QPS가 떨어졌는지, Disk I/O는 얼마나 발생했는지 등) fill factor 변경에 나름 의미있는 결과가 나오지 않을까 생각한다.
아래는 추가로, MySQL 8.0.29 버전에 새롭게 추가된 Online DDL 기능에 대해 간략하게 정리한 내용을 적어본다.
8.0.34 버전까지 나온 시점에 포스팅 하기에는 늦은감이 없지 않아 있는데, 알고 있으면 나중에 분명 도움이 되리라 생각한다.
MySQL 8.0.29 Online DDL
MySQL 8.0.29 버전 이전에는 컬럼을 포지셔닝해서 추가하거나, 삭제할 때 INSTANT 방식으로는 수행이 불가하였다. 하지만 8.0.29 버전부터는 해당 작업을 INSTANT 방식으로 수행할 수 있게 변경되었다.
핵심은 아래 2가지이다.
- ADD new column(s) at "any position" to a table with ALGORITHM=INSTANT
- DROP existing column(s) from "any position" from a table with ALGORITHM=INSTANT
> don't touch any row but update the metadata only
ref. https://blogs.oracle.com/mysql/post/mysql-80-instant-add-drop-columns
테스트
컬럼 추가 ▼
CREATE TABLE `silver` (
`id` int NOT NULL AUTO_INCREMENT,
`remark` varchar(10) DEFAULT NULL,
`created_at` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
## MySQL 8.0.26
mysql> ALTER TABLE silver ADD COLUMN updated_at DATETIME AFTER remark, ALGORITHM=instant;
ERROR 1845 (0A000): ALGORITHM=INSTANT is not supported for this operation. Try ALGORITHM=COPY/INPLACE.
## MySQL 8.0.31
mysql> ALTER TABLE silver ADD COLUMN updated_at DATETIME AFTER remark, ALGORITHM=instant;
Query OK, 0 rows affected (0.06 sec)
컬럼 삭제 ▼
## MySQL 8.0.26
mysql> ALTER TABLE silver DROP COLUMN remark, ALGORITHM=instant;
ERROR 1845 (0A000): ALGORITHM=INSTANT is not supported for this operation. Try ALGORITHM=COPY/INPLACE.
## MySQL 8.0.31
mysql> ALTER TABLE silver DROP COLUMN remark, ALGORITHM=instant;
Query OK, 0 rows affected (0.06 sec)
동작 방식
레코드 헤더의 info flag 값 4bit 중에 1bit를 사용하지 않고 있었는데, 이 1bit를 행 버전이 있다는 것을 나타내는데 사용하도록 변경함. 비트 값이 채워지면(활성화되면) 레코드 헤더에 행 버전이 저장됨
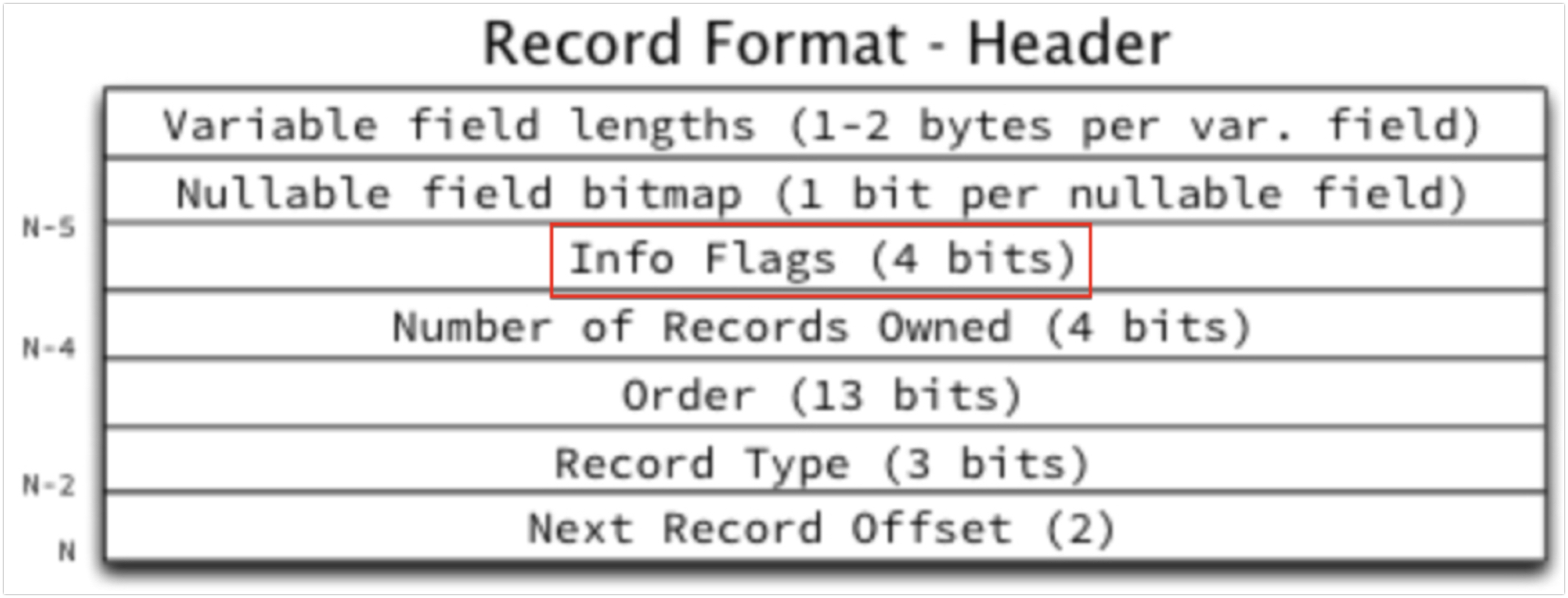
제한사항
- 최대 64번까지 ALTER TABLE … ADD/DROP 가능 (version limit 64)
- 전문 인덱스가 존재하는 테이블에 사용 불가능
- row_format이 compressed인 경우 사용 불가능
- 임시 테이블은 사용 불가능
→ 현재는 행 버전이 64로 제한되어 있으나 추가 요청 시, 다음 릴리즈 버전에 적용할 수도 있음
ROW VERSION 확인 ▼
mysql> CREATE TABE silver(seq1 INT);
mysql> SELECT NAME,TOTAL_ROW_VERSIONS FROM INFORMATION_SCHEMA.INNODB_TABLES WHERE NAME LIKE "test/silver";
+-------------+--------------------+
| NAME | TOTAL_ROW_VERSIONS |
+-------------+--------------------+
| test/silver | 0 |
+-------------+--------------------+
mysql> ALTER TABLE silver ADD COLUMN seq2 INT, ALGORITHM=instant;
+-------------+--------------------+
| NAME | TOTAL_ROW_VERSIONS |
+-------------+--------------------+
| test/silver | 1 |
+-------------+--------------------+
...
...
...
...(omitted)
mysql> ALTER TABLE silver ADD COLUMN seq66 INT, ALGORITHM=instant;
ERROR 4092 (HY000): Maximum row versions reached for table test/silver. No more columns can be added or dropped instantly. Please use COPY/INPLACE.
mysql> SELECT NAME,TOTAL_ROW_VERSIONS FROM INFORMATION_SCHEMA.INNODB_TABLES WHERE NAME LIKE "test/silver";
+-------------+--------------------+
| NAME | TOTAL_ROW_VERSIONS |
+-------------+--------------------+
| test/silver | 64 |
+-------------+--------------------+
mysql> OPTIMIZE TABLE silver;
mysql> SELECT NAME,TOTAL_ROW_VERSIONS FROM INFORMATION_SCHEMA.INNODB_TABLES WHERE NAME LIKE "test/silver";
+-------------+--------------------+
| NAME | TOTAL_ROW_VERSIONS |
+-------------+--------------------+
| test/silver | 0 |
+-------------+--------------------+'MySQL' 카테고리의 다른 글
| MySQL 버그 리포트 찾는 방법(MySQL 8.0 Default Collation) (2) | 2023.10.28 |
|---|---|
| MySQL RAND 함수의 난수 생성 원리 (0) | 2023.08.20 |
| pt-online-schema-change PK & DROP Test (0) | 2023.08.19 |
| MySQL 인덱스 스킵 스캔(Index Skip Scan)의 원리 (0) | 2023.08.13 |
| Aurora Version & Status 터미널 대시보드 (0) | 2023.08.11 |

