여기저기 설명되어 있는 MySQL의 인덱스 스킵 스캔(index skip scan)을 이야기 하고자 하는 것은 아니고, 좀 더 확실한 원리를 설명하려고 글을 적어본다.
인덱스 스킵 스캔 최적화가 적용될 때 먼저 유니크한 키 값(distinct prefix)을 전부 조회해서 쿼리에 적용하는 걸까.
예를 들어 gender라는 컬럼에 유니크한 값으로 M(Male)과 F(Female)가 있다고 가정하자. (인덱스는 gender, f2 복합 인덱스)
아래 쿼리가 수행되면, 인덱스 스킵 스캔은 먼저 유니크한 키 값을 전부 조회하는 것이 아니라 첫 번째 유니크한 값을 찾는 작업부터 수행한다.
SELECT gender, f2 FROM t1 WHERE f2 > 40;
첫 번째 유니크한 값을 찾는 방법은 여러가지가 있겠지만, 가장 간단한 방법은 인덱스의 첫 번째 레코드를 읽는 것이다. 인덱스의 첫 번째 레코드는 유니크한 키 값을 보장하기 때문에 (인덱스 풀스캔이 첫 번째 레코드부터 읽는 것처럼) 인덱스 스킵 스캔도 인덱스의 첫 번째 레코드를 읽는다. 그래서 첫 번째 레코드를 읽고 첫 번째 유니크한 값 M을 얻는다.
그럼 두 번째 유니크한 키 값은 어떻게 찾을까?
우선 그 전에 첫 번째 유니크한 키 값을 검색한 사실을 기억해야할 필요가 있다. MySQL 서버는 첫 번째 유니크한 값을 그대로 두지 않는다. 인덱스를 사용해서 데이터를 조회할 준비를 마쳤기 때문에 쿼리 하위 조건에 맞는 다음 레코드를 읽는다. 쿼리로 표현하면 아래와 같다.
SELECT gender, f2 FROM t1 WHERE gender = 'M' AND f2 > 40;
위 작업을 끝마쳐야 두 번째 유니크한 키 값을 읽을 수 있는 것이다. 유니크한 키 값을 전부 조회해서 하나하나 대입하여 쿼리를 수행하는 것이 아니다.
아래는 이를 확인하기 위해 인덱스 스킵 스캔을 디버깅한 내용이다.
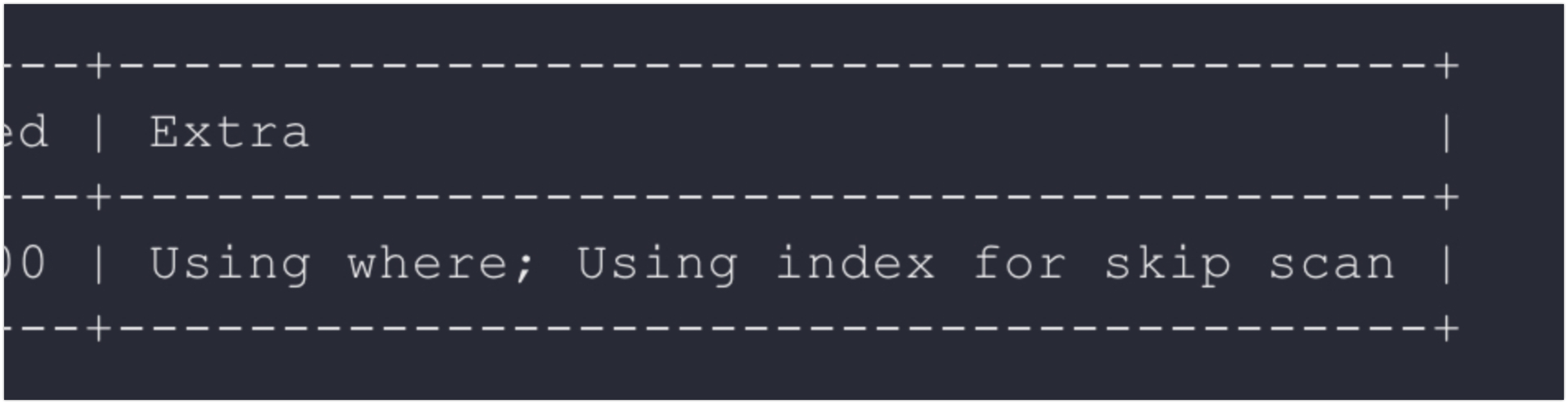
먼저 실행계획으로 인덱스 스킵 스캔 최적화가 사용되는 것을 확인한 후 디버깅을 시작한다. 아래와 같이 Extra 필드에 Using index for skip scan이 표기되면 인덱스 스킵 스캔 최적화가 적용된 것이다. ▼
인덱스 스킵 스캔과 직접적인 연관은 없지만 잠시 디버깅 얘기를 좀 해보자. MySQL 서버를 디버깅할 수 있는 방법은 크게 3가지이다. 첫 번째는 Server 디버깅 옵션으로 MySQL 서버를 시작하는 방법, 두 번째는 Client 디버깅 옵션으로 MySQL 서버를 시작하는 방법, 세 번째는 디버깅 툴로 MySQL 서버를 디버깅 하는 방법이다.
첫 번째와 두 번째 방법은 직접 해보면 알겠지만 MySQL 서버를 디버깅 하는데 있어서 크게 도움이 되지 않는다. 필터링 해야할 트레이스가 많기 때문에 원하는 데이터를 얻기가 힘들뿐더러 자세하게 설명되어 있지도 않다. Client 디버깅은 덜한데, Server 디버깅은 트레이스양이 너무 많아서 디스크 용량 압박을 받게 될 것이다. 테이블을 생성하고 데이터를 넣고 쿼리를 수행하는 아주 간단한 작업이 끝난 후 트레이스 파일의 용량을 확인해보면 기겁한다. 또 debug 모드를 수행하기 위해서는 디버그용으로 빌드를 다시 해줘야 하는 귀찮음이 있다.
아래는 MySQL 서버 디버깅 모드로 mysqld 프로세스를 띄우고, 테이블을 생성 후 데이터를 넣고 쿼리를 조회한 것이다. ▼

/tmp 디렉터리에 들어가보면 벌써 1GB나 넘게 차버린 mysqld.trace 파일을 확인할 수 있다. ▼

때문에 인덱스 스킵 스캔 최적화를 확인하기 위한 디버깅 방법은 세 번째 방법으로 진행한다.
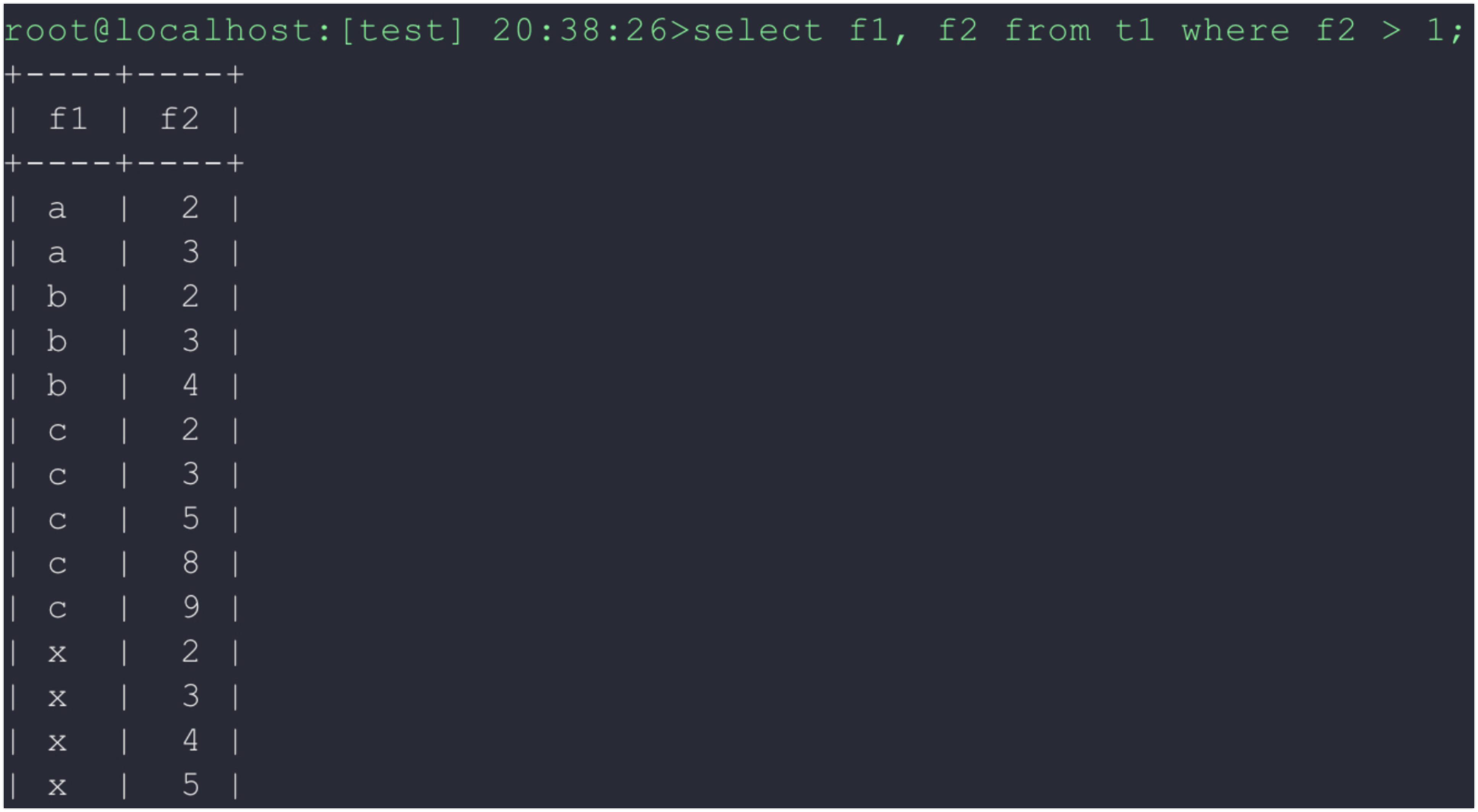
테스트 데이터 및 쿼리는 아래와 같다. ▼
(a, 2), (a, 3), (b, 2), (b, 3), (b, 4) 레코드가 인덱스 스킵 스캔 최적화를 통해 어떻게 읽히는지 한 번 확인해보자.
LLDB MySQL Debugging for index skip scan
유닉스 환경에서 지원하는 디버깅 툴은 많지만 나는 MacOS에 기본으로 설치되어있는 lldb로 디버깅을 수행했다. (이외 gdb, kDbg, Nemiver, Xdebug등이 있다.)
먼저 아래와 같이 mysqld 프로세스를 lldb로 수행한다.
sudo lldb mysqld
그러면 아래와 같이 mysqld 프로세스가 실행 가능한(executable) 형태로 lldb에 의해 로드된다. ▼

MySQL 서버의 인덱스 스킵 스캔 코드는 mysql-server/sql/range_optimizer/index_skip_scan.cc 파일에 구현되어 있다. 그리고 그 안에서 다시 int IndexSkipScanIterator::Read() 함수를 사용한다.
때문에 브레이크 포인트(Break Point)는 아래와 같이 index_skip_scan.cc:259에 걸어준다. ▼
(259 라인은 int IndexSkipScanIterator::Read() 함수 바로 위 라인이다.)

그 다음 run 명령으로 mysqld 프로세스를 시작한다. ▼

이제 mysqld 프로세스가 기동 중이기 때문에 다른 터미널 창을 열고 MySQL Client로 MySQL 서버에 접속한다. 그리고 인덱스 스킵 스캔 최적화가 수행될 수 있도록 쿼리를 수행해준다. 그러면 쿼리가 수행되지 않고 브레이크 포인트에서 멈추게 되는 것을 확인할 수 있다. ▼

아래를 보면 int IndexSkipScanIterator::Read() 함수 시작 부분에서 프로세스 진행이 멈춘 것이 보인다. ▼

(a, 2) 레코드를 읽는 과정
여기서부터 인덱스 스킵 스캔이 어떻게 흘러가는지에 대해서 확인을 쭉 해보면 되는데..
먼저, 맨 위에서 설명했던 이 부분을 확인해보자.
"인덱스 스킵 스캔은 먼저 유니크한 키 값을 전부 조회하는 것이 아니라 첫 번째 유니크한 값을 찾는 작업부터 수행한다."
next 명령을 사용하여 코드를 한 줄 한 줄 수행하다 보면, 아래 275번째 라인의 table()->file->ha_index_first(table()->record[0]) 코드가 보인다. 이 함수를 호출하면 테이블 인덱스에서 가장 작은 값을 찾을 수 있다. ▼
(lldb는 이전 마지막 명령을 기억하기 때문에 next는 한 번만 입력하고 엔터만 눌러주면 된다.)
274번째 라인 위치에서 m read table()->record[0] 명령을 통해 메모리 주소의 값을 읽었을 때는 값이 비어있다가,
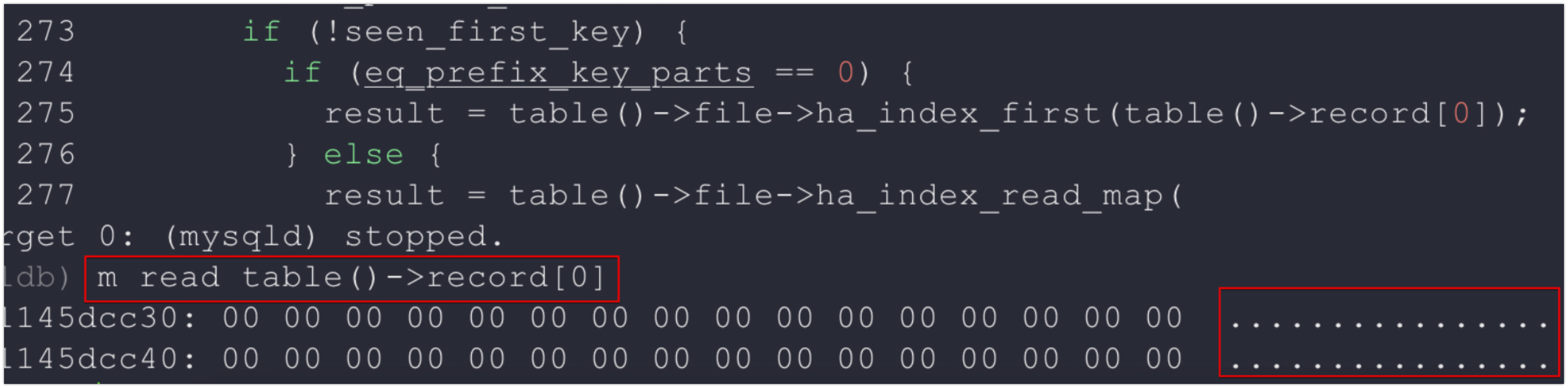
275번째 라인이 수행된 후에는 table()->record[0] 버퍼에 'a' 값이 담긴 것을 확인할 수 있다. 그리고 이 작업은 인덱스의 첫 번째 레코드 키 값을 읽은 것이기 때문에 최초 한 번만 수행되고 이후 루틴에서는 수행되지 않는다. ▼

그리고 나서 인덱스의 첫 번째 레코드 키 값을 읽었기 때문에 seen_first_key 변수 주소 위치에 true를 설정한다. ▼

ha_index_first() 함수로 찾은 첫 번째 키 값은 다음 키 값을 찾을 때 사용하기 위해 key_copy() 함수로 distinct_prefix 변수에 복사한다. 이 값은 이후 코드에서 f1='a' 범위 내에 해당하는 첫 번째 레코드를 읽는 작업을 수행할 때도 사용된다. ▼

이후 몇 몇 소스 라인을 수행하다보면 367번째 다다르게 되는데, 이 라인의 ha_read_range_first() 함수는 start_key와 end_key 범위 내에 있는 첫 번째 레코드를 반환해주는 역할을 한다. 즉 위에서 말한 f1='a' 에 해당하는 첫 번째 레코드를 읽는다. ▼

이어서 뒤의 몇 개의 소스 코드를 수행하면 (a, 2) 레코드를 찾는 작업은 끝이 난다.
이를 간단히 정리하면 다음과 같다.
/* Phase 1
첫 번째 키 값: a
1) ha_index_first(table()->record[0]) #인덱스 레코드의 첫 번째 키 값을 찾는다.
2) ha_read_range_first() #키 값에 해당하는 첫 번째 레코드를 읽는다.
--> (a, 2) 레코드를 찾음
*/
(a, 3) 레코드를 읽는 과정
1개 레코드를 읽게 되면 index_skip_scan.cc --> composite_iterators.cc --> sql_union.cc 파일 순으로 넘어가게 되는데, finish 명령어를 사용하면 소스 파일 단위로 수행 단계를 건너뛸 수 있다. 그러면 다시 index_skip_scan.cc 파일로 되돌아온다.
두 번째 레코드를 읽는 과정은 간단하다. f1='a' 라는 인덱스 프리픽스를 만족한 상태이기 때문에 272번째 라인의 if문은 패스하고,
else문으로 넘어가서 378번째 라인의 ha_read_range_next() 함수를 호출하게 된다. 이 함수는 단순히 다음 레코드를 읽는 역할을 한다. 다음 레코드는 (a, 3)이기 때문에 (a, 3) 레코드를 읽는 과정은 여기서 끝이 난다.

이를 다시 첫 번째 레코드를 읽는 과정까지 누적하여 정리하면 다음과 같다.
/* Phase 1
첫 번째 키 값: a
1) ha_index_first(table()->record[0]) #인덱스 레코드의 첫 번째 키 값을 찾는다.
2) ha_read_range_first() #키 값에 해당하는 첫 번째 레코드를 읽는다.
--> (a, 2) 레코드를 찾음
*/
/* Phase 2
첫 번째 키 값: a
1) ha_read_range_next()
--> (a, 3) 레코드를 찾음
*/
(b, 2) 레코드를 읽는 과정
위의 테스트 데이터를 보면 알겠지만 (a, 3) 레코드 다음에 읽어야할 레코드는 (b, 2) 이다. 눈치챘겠지만 인덱스 프리픽스 값이 a에서 b로 변경되었다. 인덱스의 유니크한 값이 변경되었기 때문에 여기서부터 옵티마이저 최적화 단계가 추가된다.
우선은 ha_read_range_next() 함수를 통해서 다음 레코드를 읽는 작업 중이었기 때문에 이번 Phase에서도 동일하게 ha_read_range_next() 함수를 호출한다. 대신에 다음 레코드가 무엇이 되었건 f1='a' and f2 > 1 에 대한 범위 검색이 종료된 경우에는 result에 0이 아닌 값을 반환하고, 이는 HandleError() 함수를 통해 error_code가 -1인지 아닌지를 판단한다. ▼

HandleError 함수를 호출하는 부분으로 들어가면, basic_row_iterators.cc 파일에서 error 번호가 HA_ERR_END_OF_FILE과 일치하는지 확인하고 일치하면 return 값으로 -1을 반환한다. HA_ERR_END_OF_FILE은 f1='a' and f2 > 1 조건으로 범위 검색이 끝났음을 의미한다.

그리고 더 이상 f1='a' 인덱스 프리픽스는 유효하지 않은 프리픽스이기 때문에 index_skip_scan.cc 파일의 382번째 라인에서 is_prefix_valid 값을 false로 설정한다. 이어지는 코드가 continue 이기 때문에 do~while 반복문을 다시 실행한다.
is_prefix_valid 값은 false이고, 첫 번째 인덱스 키 값(seen_first_key)은 이미 본 상태이기 때문에, ▼

283번째 라인의 else문으로 넘어가면서 index_next_different 라는 함수를 호출하게 된다. ▼ (modified by silver 주석은 커스텀 빌드를 위해 적어놓은 것이니 무시)

이 함수는 인덱스 스킵 스캔 최적화를 위해 사용되는 함수이기 때문에 호출 시 range_optimizer.cc 파일의 index_next_different 함수를 사용하게 된다. 한 가지 특이점은 첫 번째 인자 값으로 false를 고정 값으로 전달하고 있다는 사실이다.
range_optimizer.cc 파일을 보면 is_index_scan 매개변수로 인자 값 false를 전달받고 있는 것을 확인할 수 있다. ▼

range_optimizer.cc 파일의 is_index_scan 매개변수 설명을 보면 다음과 같이 나온다. ▼
"hint to use index scan instead of random index read to find the next different value."
다음의 다른 값을 찾기 위해 랜덤 인덱스 읽기 대신에 인덱스 스캔을 사용하는 힌트

즉 is_index_scan 값이 true이면 인덱스 스캔을 해서 다른 키 값을 찾는 것이고, false이면 랜덤 인덱스 스캔을 해서 다른 키 값을 찾는 것이다. 유니크 한 키 값의 개수가 적고 레코드 건 수가 많은 경우에는 인덱스 스캔을 해서 다른 키 값을 찾는 것보다 랜덤 인덱스 스캔을 통해서 다른 키 값을 찾는 것이 훨씬 효율적인 것이다. 때문에 인덱스 스킵 스캔은 false를 고정적으로 가져가고 있다고 나는 생각한다. (뭔가 아직 완벽한 것 같진 않지만)
어쨌든 is_index_scan 값이 false이면 아래와 같이 1390번째 라인의 ha_index_read_map() 함수를 호출하게 된다. 이 때 일종의 맵을 생성해서 다음 인덱스 키 값을 찾게 되는데 이 때 flag 값으로 HA_READ_AFTER_KEY 인자 값을 넘기면서 현재의 인덱스 키 값보다 큰 다음의 키 값을 찾도록 명령한다. 그 기준이 되는 인덱스 키 값은 group_prefix로 전달된다. 현재 예에서는 group_prefix의 인자 값으로 'a' 가 전달된다.
(번외로 현재의 인덱스 키 값보다 이전 레코드 키 값을 찾기 위해서는 flag에 HA_READ_BEFORE_KEY를 던져주어야 한다.)

이렇게 다음 인덱스 키 값을 찾는 작업은 range_optimizer.cc --> handler.cc --> ha_innodb.cc 순으로 흘러간다. 그래서 결과적으로 record변수에 다음 인덱스 키 값을 담는다. 사실 ha_index_read_map() 함수를 사용해서 다음 인덱스 키 값을 얻어오는 과정에 대해 좀 더 이야기해야 할 부분이 있는데, 우선은 여기까지의 흐름만 알고 있으면 될 것 같다.
위에서 인덱스 스킵 스캔을 통해 두 번째 인덱스 프리픽스 값 b를 찾은 이후에는 f1='b' 에 해당하는 첫 번째 레코드를 읽어오는 작업을 수행한다. (a, 2) 레코드를 읽어오는 작업과 동일하다. ▼

이것으로 인덱스 스킵 스캔을 통해 a 다음의 b 키 값을 읽고, (b, 2) 레코드를 읽는 작업까지의 과정이 끝이 난다.
현재까지 과정을 정리하면 다음과 같다.
/* Phase 1
첫 번째 키 값: a
1) ha_index_first(table()->record[0]) #인덱스 레코드의 첫 번째 키 값을 찾는다.
2) ha_read_range_first() #키 값에 해당하는 첫 번째 레코드를 읽는다.
--> (a, 2) 레코드를 찾음
*/
/* Phase 2
첫 번째 키 값: a
1) ha_read_range_next() #다음 레코드를 읽는다.
--> (a, 3) 레코드를 찾음
*/
/* Phase 3
두 번째 키 값: b
1) ha_read_range_next() #다음 레코드를 읽고, f1='a' and f2 > 1 검색이 종료된 것을 확인한다.
--> loop를 벗어나지 않음
*/
/* Phase 4
두 번째 키 값: b
1) index_next_different() --> ha_index_read_map() #a 다음의 유니크한 인덱스 레코드 키 값을 찾는다.
2) ha_read_range_first #키 값에 해당하는 첫 번째 레코드를 읽는다.
--> (b, 2) 레코드를 찾음
*/
(b, 3), (b, 4) 레코드를 읽는 과정
이 과정은 (a, 3) 레코드를 검색할 때 과정과 동일하게 진행되고, 그 다음 인덱스 레코드 키 값 c를 찾을 때는 b 키 값을 찾는 과정이 동일하게 반복된다.
여기까지 작업을 다시 정리하면 다음과 같다.
/* Phase 1
첫 번째 키 값: a
1) ha_index_first(table()->record[0]) #인덱스 레코드의 첫 번째 키 값을 찾는다.
2) ha_read_range_first() #키 값에 해당하는 첫 번째 레코드를 읽는다.
--> (a, 2) 레코드를 찾음
*/
/* Phase 2
첫 번째 키 값: a
1) ha_read_range_next() #다음 레코드를 읽는다.
--> (a, 3) 레코드를 찾음
*/
/* Phase 3
두 번째 키 값: b
1) ha_read_range_next() #다음 레코드를 읽고, f1='a' and f2 > 1 검색이 종료된 것을 확인한다.
--> loop를 벗어나지 않음
*/
/* Phase 4
두 번째 키 값: b
1) index_next_different() --> ha_index_read_map() #a 다음의 유니크한 인덱스 레코드 키 값 b를 찾는다.
2) ha_read_range_first #키 값에 해당하는 첫 번째 레코드를 읽는다.
--> (b, 2) 레코드를 찾음
*/
/* Phase 5
두 번째 키 값: b
1) ha_read_range_next() #다음 레코드를 읽는다.
--> (b, 3) 레코드를 찾음
*/
/* Phase 6
두 번째 키 값: b
1) ha_read_range_next() #다음 레코드를 읽는다.
--> (b, 4) 레코드를 찾음
*/
/* Phase 7
세 번째 키 값: c
1) ha_read_range_next() #다음 레코드를 읽고, f1='b' and f2 > 1 검색이 종료된 것을 확인한다.
--> loop를 벗어나지 않음
*/
/* Phase 8
세 번째 키 값: c
1) index_next_different() --> ha_index_read_map() #b 다음의 유니크한 인덱스 레코드 키 값 c를 찾는다.
2) ha_read_range_first #키 값에 해당하는 첫 번째 레코드를 읽는다.
--> (c, 2) 레코드를 찾음
*/
/* Phase 9
세 번째 키 값: c
1) ha_read_range_next() #다음 레코드를 읽는다.
--> (c, 3) 레코드를 찾음
.
.
.
(반복)
*/
결론
인덱스 스킵 스캔이 동작하는 방식을 디버깅을 통해 알아보았는데, 인덱스 스킵 스캔 동작 방식에 대해 잘못 알고 있었던 부분들이 꽤나 많았던 것 같다.
다음에는 is_index_scan 인자 값을 true로 변경하여 빌드하고, 랜덤 인덱스 읽기가 아니라 인덱스 스캔을 사용하여 다음 키 값을 찾게되면 동작방식이 어떻게 달라지는지 이야기해보면 좋을 것 같다.
Reference
https://github.com/mysql/mysql-server/blob/8.0/sql/range_optimizer/index_skip_scan.cc
https://github.com/mysql/mysql-server/blob/8.0/sql/range_optimizer/range_optimizer.cc
https://github.com/mysql/mysql-server/blob/8.0/sql/handler.cc
https://github.com/mysql/mysql-server/blob/8.0/storage/innobase/handler/ha_innodb.cc
https://dev.mysql.com/doc/dev/mysql-server/latest/internal_8h.html#ae103eece1899af4f2dc8795b966e6567
'MySQL' 카테고리의 다른 글
| MySQL 버그 리포트 찾는 방법(MySQL 8.0 Default Collation) (2) | 2023.10.28 |
|---|---|
| MySQL RAND 함수의 난수 생성 원리 (0) | 2023.08.20 |
| Aurora MySQL Fragmentation Test & Online DDL (0) | 2023.08.19 |
| pt-online-schema-change PK & DROP Test (0) | 2023.08.19 |
| Aurora Version & Status 터미널 대시보드 (0) | 2023.08.11 |
